Инструкция по интеграции: PII Proxy Wrapper
Что это
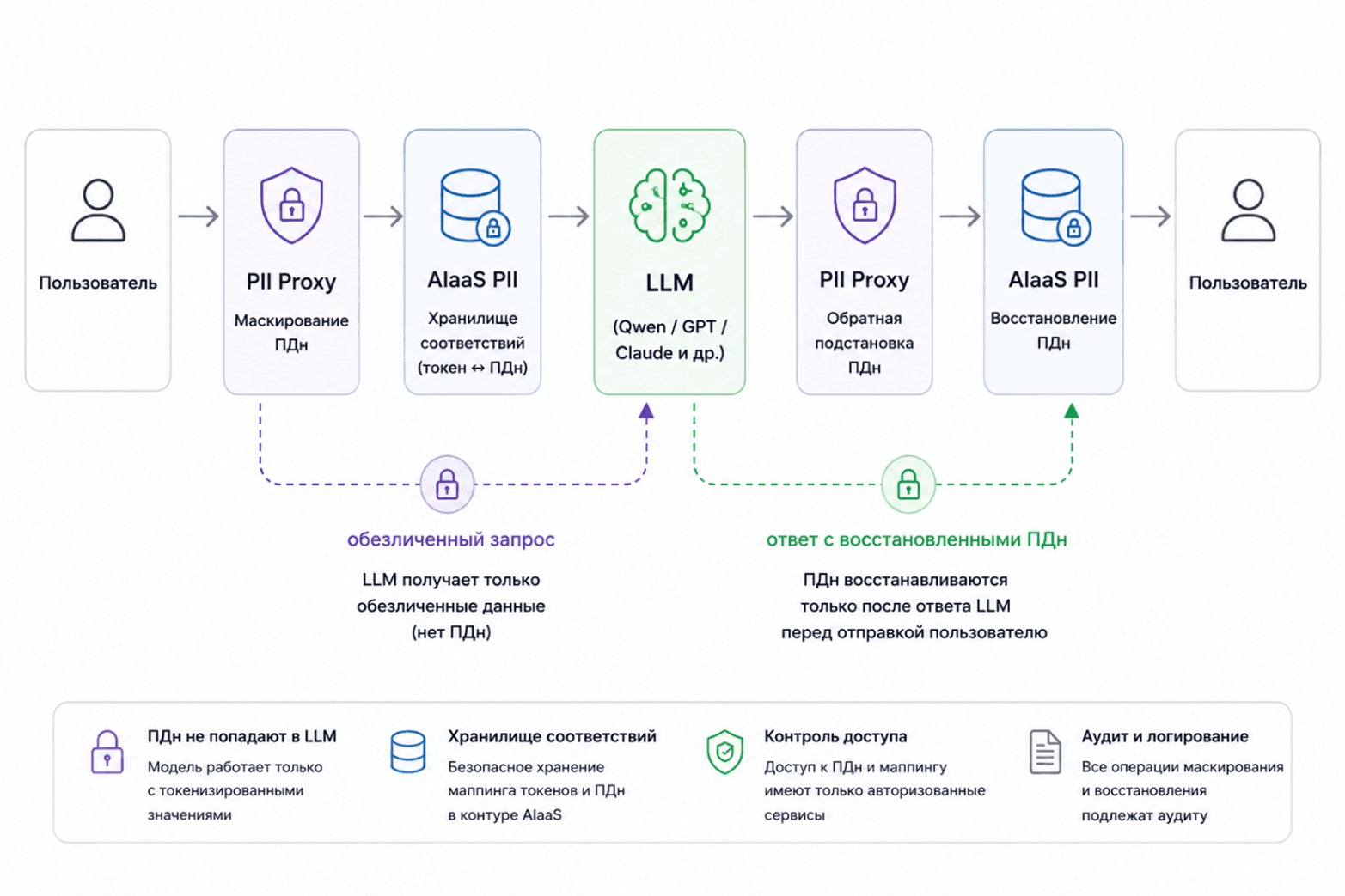
PII Proxy — тонкая программная прослойка между вашим приложением и LLM-провайдером, которая автоматически обнаруживает и обезличивает персональные данные в запросах перед отправкой в нейросеть, а затем восстанавливает их в ответе.
Ваше приложение общается с прокси как с обычным OpenAI-совместимым API — формат запросов не меняется. Прокси берёт на себя всю логику PII-защиты.
Проблема
При передаче пользовательских данных в публичные LLM (OpenAI, OpenRouter, Claude) вы теряете контроль над чувствительной информацией. Данные уходят за периметр вашей инфраструктуры. PII Proxy решает эту проблему: LLM видит только обезличенный текст. Персональные данные проходят через неё транзитно, но сама нейросеть их не получает.
Как это работает
|
|
Шаг
|
Куда
|
Что происходит
|
1
|
NER
|
POST /v1/ner
|
Обнаружение ПДн в тексте: ФИО, телефон, email, адрес, паспорт, даты
|
2
|
Mask
|
POST /v1/mask
|
Замена найденных ПДн на плейсхолдеры вида *N_LABEL *, получение mapping-словаря
|
3
|
LLM
|
Ваш LLM-провайдер
|
Обезличенный текст уходит в нейросеть. LLM не получает ПДн
|
4
|
Unmask
|
POST /v1/unmask
|
Плейсхолдеры в ответе LLM заменяются на исходные значения из mapping
Интеграция: полный код обёртки
import json
import requests
class PIIProxy:
"""
Прозрачная прокси-обёртка: ваш код → PII-очистка → LLM → PII-восстановление.
Интерфейс совместим с OpenAI /chat/completions.
"""
AINERGY_URL = "https://ainergy01-api-am2.itglobal.com"
def __init__(self, ainergy_token: str, llm_base_url: str, llm_api_key: str):
self.ainergy_headers = {
"Authorization": f"Bearer {ainergy_token}",
"X-AIN-USERNAME": "<ваш-username>",
"X-AIN-SOURCEID": "<ваш-source-id>",
"Content-Type": "application/json",
}
self.llm_base_url = llm_base_url.rstrip("/")
Быстрый старт
proxy = PIIProxy(
ainergy_token="<ваш-AInergy-токен>",
llm_base_url="https://xxxxxx",
llm_api_key="<ваш-ключ-LLM>",
)
response = proxy.chat_completion({
"model": "openai/gpt-4.1",
"messages": [{
"role": "user",
"content": "Меня зовут Степан Сергеевич, email: stepa@example.com"
}]
})
print(response ["choices"][0]["message"]["content"])
# Вывод: ответ LLM с восстановленными ФИО и email
Пример работы
Входные данные
Паспортная анкета из 17 полей: ФИО, дата рождения, паспорт, адрес, СНИЛС, ИНН, телефон, email, место работы, автомобиль и т.д.
Этап 1: NER — обнаружено 17 сущностей
PHONE_NUMBER +7 (900) 000-00-00 score=0.986
PHONE_NUMBER +7 (900) 111-11-11 score=0.993
EMAIL demo.person@example.com score=0.975
SURNAME Тестов score=0.459
CITY г. Демоград score=0.863
CITY г. Демоград score=0.936
CITY г. Демоград score=0.964
COUNTRY РФ score=0.973
STREET ул. Примерная / проспект Тестовый score=0.637 / 0.449
PASSPORT_NUMBER 000000 score=0.589
SNILS 000-000-000 00 score=0.487
JOB_TITLE специалист по тестовым данным score=0.896
JOB отдел проверки форматов score=0.636
DATE 01.01.2020 score=0.614
YEAR 2022 score=0.940
Этап 2: Mask — текст обезличен
До: ФИО: Иван Александрович Тестов, тел: +7 (900) 000-00-00, email: demo.person@example.com...
После: ФИО: *NAME * *0_SURNAME *, тел: *1_PHONE_NUMBER *, email: *2_EMAIL *...
Этап 3: LLM — GPT-4.1 обрабатывает обезличенный текст
LLM видит: ФИО: *0_SURNAME *... и не имеет доступа к реальным данным.
Этап 4: Unmask — ПДн восстановлены
Ответ LLM после восстановления:
ФИО: Иван Александрович Тестов
Дата рождения: 14.03.1991
Паспорт: серия 0000 номер 000000
Телефон: +7 (900) 000-00-00
E-mail: demo.person@example.com
...
Метрики цикла
|
Параметр
|
Значение
|
Объём текста
|
818 символов, 17 полей ПДн
|
Токенов на NER (raw)
|
1 180
|
Найдено сущностей
|
17
|
Mapping (плейсхолдеров)
|
14
|
Токенов LLM (prompt+completion)
|
733
|
End-to-end latency
|
~5 секунд
Особенности эксплуатации
Типы обнаруживаемых сущностей
Модель надёжно определяет следующие категории ПДн:
EMAIL — адреса электронной почты (точность 97–99%)
PHONE_NUMBER — телефонные номера в любом формате (точность 97–99%)
CITY — названия городов (точность 86–96%)
COUNTRY — названия стран (точность 97%)
DATE — даты (точность ~60%)
YEAR — года (точность 94%)
JOB_TITLE — должности (точность 89%)
JOB — места работы (точность ~64%)
PERSON_NAME — имена и фамилии (точность 46–89%)
Дополнительная валидация
Для гарантированного покрытия полей со строгим форматом (ИНН, СНИЛС, паспортные серии) рекомендуется добавить правила в конфигурацию сервиса — файл configs/rules.yml. Это позволяет комбинировать AI-детекцию с детерминированными regex-паттернами без изменения клиентского кода.
Формат восстановленных данных
Unmask по умолчанию оборачивает восстановленные значения в скобки: Тестов → [Тестов]. Это визуальный маркер, указывающий конечному пользователю, что данные прошли цикл обезличивания. При необходимости формат можно настроить в конфигурации сервиса.
Тарификация
Услуга PII-очистки тарифицируется в А-токенах по формуле:
А-токены = input_tokens × coefficient
|
Объём текста
|
Raw-токены
|
~А-токенов (coeff=0.001)
|
1 предложение (ФИО + email + телефон)
|
130
|
0.13
|
Паспортная анкета (17 полей, 818 символов)
|
1 180
|
1.18
|
Развёрнутый текст (~5 000 символов)
|
~5 000
|
~5
Рекомендации по внедрению
Streaming (SSE)
При использовании потокового режима (stream=true) накапливайте чанки LLM-ответа, затем выполните один вызов unmask на полном тексте. Либо — unmask каждого чанка отдельно (работает, если mapping уже полный).
Tool calling / Function calling
Аргументы, которые LLM передаёт в вызовы функций (tool_calls), могут содержать ПДн. Прокси поддерживает их маскирование и восстановление.
RAG / Embeddings
Если вы векторизуете пользовательские запросы для RAG — обезличивайте их перед эмбеддингом и сохраняйте mapping для обратной замены в извлечённых чанках.
Конфиденциальность
Все вызовы PII API (NER, Mask, Unmask) выполняются внутри контура ITGLOBAL.COM. ПДн не покидают инфраструктуру облачного провайдера.